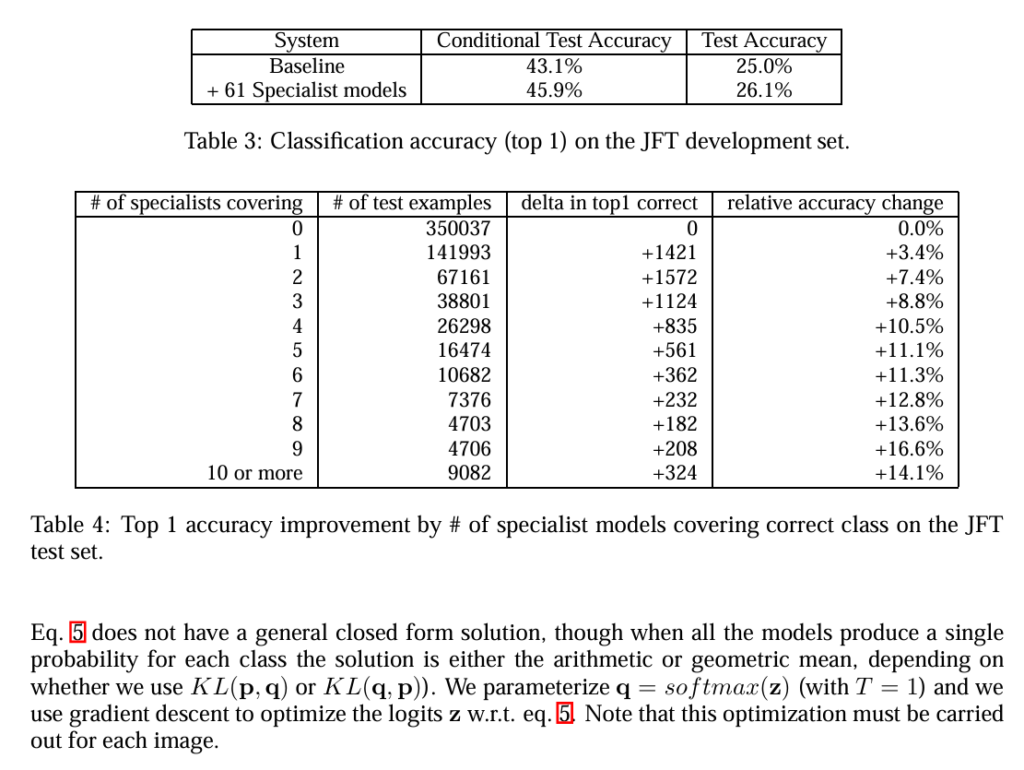
Background or Motivation:
CNN은 ImageNet 대규모 데이터셋에서 큰 성공을 거두었으나, 네트워크가 점점 더 깊어지고 복잡해지면서 FLOPs 계산 비용과 Parameter 저장 비용이 크게 증가했다. 모바일 기기나 실시간 이미지 처리 서비스에서는 정확도뿐만 아니라 추론 속도와 모델 크기가 매우 중요하다. 기존 연구에서 Weights Pruning 이나 Low Rank Approx., Quantization, Compression 기법을 통해서 모델을 압축했으나, Fully Connected Layer에 효과적이었고 Convolution Layer의 실제 계산 비용이 낮아지는 것은 제한적이다.
즉, Convolution Layer의 계산 비용을 효과적으로 줄이면서, 불규칙한 희소를 만들지 않는 방법을 찾는 것이 이 연구의 배경이다.
Problem:
-> Magnitude-based weight pruning(Han et al., 2015) FC Layer에서 많은 파라미터를 줄였지만, Conv Layer에서 Irregular sparsity가 발생해 실제 계산 속도 향상이 미미함.
-> Conv Layer의 계산 비용이 전체 FLOP의 대부분을 차지하는데 이를 구조적으로 줄이기는 어렵다.
-> Layer by Layer의 Iterative pruning과 Fine-tuning은 시간이 많이 소요된다.
깊은 네트워크를 가진 모델, ResNet에서는 비효율적이다.
-> 기존 연구에서 작은 가중치를 제거하는 방식은 Filter 전체를 제거하지 않아 계산량 감소가 제한적이다.
Proposal:
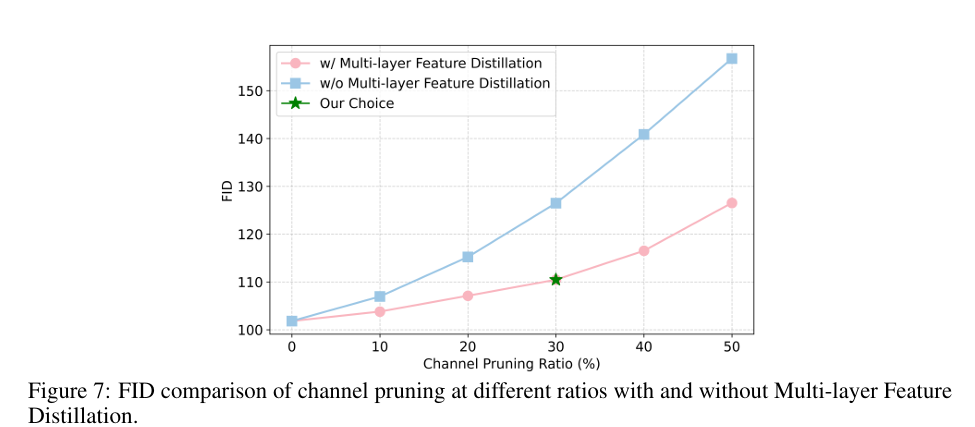
전체 Filter와 Feature Map을 한 번에 제거하는 Structured Pruning 방법.
주요 기법은
1. Filter 중요도 평가
-> 방법은 각 Filter의 L1-Norm. 을 구해서 작은 Filter를 제거.
2. Pruning 효과
-> 하나의 Filter를 제거하면 Feature Map과 next layer에서 Feature Map, Kernel도 제거되므로 =>계산량이 감소됨.
3. Pruning 전략
-> Independent vs Greedy
-> Stage-wise pruning
4. ResNet 대응
-> Residual block의 projection shortcut 등을 고려한 pruning 규칙
5. ReTraining
-> One-shot pruning(여러 layer를 동시에 pruning 하고 재학습) 하는 방법은 iterative한 방법보다는 빠르다. 다만 sensitive layer는 pruning을 skip 할 수 있다.
기대효과는 Sparsity가 발생하지 않아서 기존 Dense Matrix Multiplication도 사용 가능하고 계산속도 향상과 Pruning ratio를 쉽게 조절할 수 있음.
Conclusion:
VGG-16 (CIFAR10) : 34.2% Flops 감소(파라미터가 64% 감소)
ResNet-56 : 27.6% 감소
ResNet-110 : 38.6% 감소
ResNet-34(ImageNet): 24.2% 감소
Filter Level의 Structured Pruning은 Sparsity 없이 Conv Layer의 계산 비용을 크게 줄일 수 있음을 입증했다.
My opinion:
Irregular sparsity가 생기는 이유는?
선행연구에서 모델을 압축했는데 FC에서는 효과가 좋았지만, Convolution Layer에서 좋지 않은 이유는? = Sparsity Layer