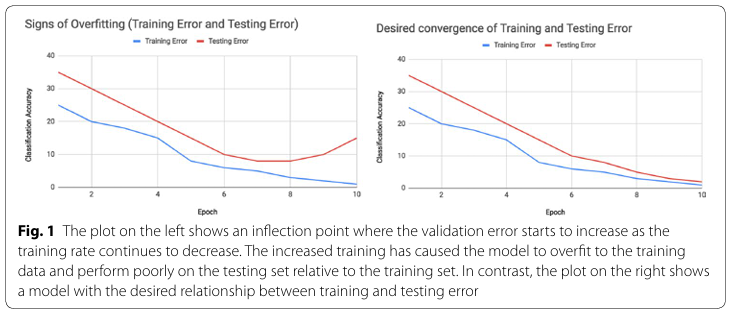
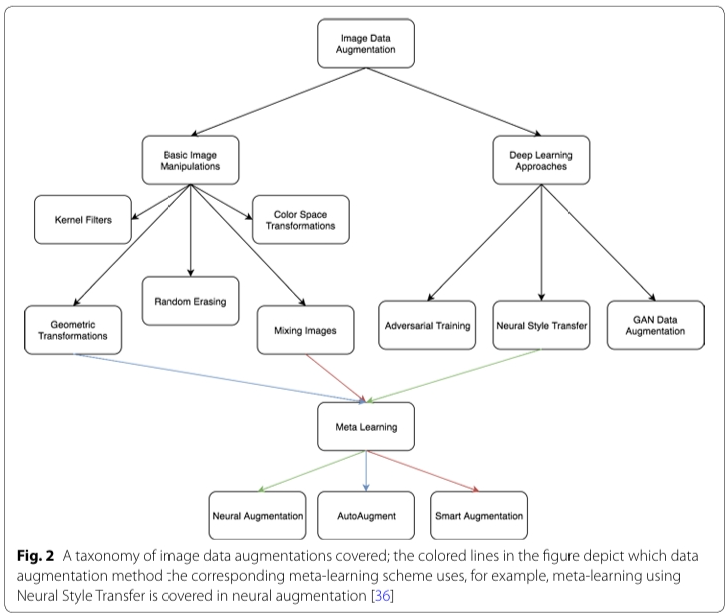
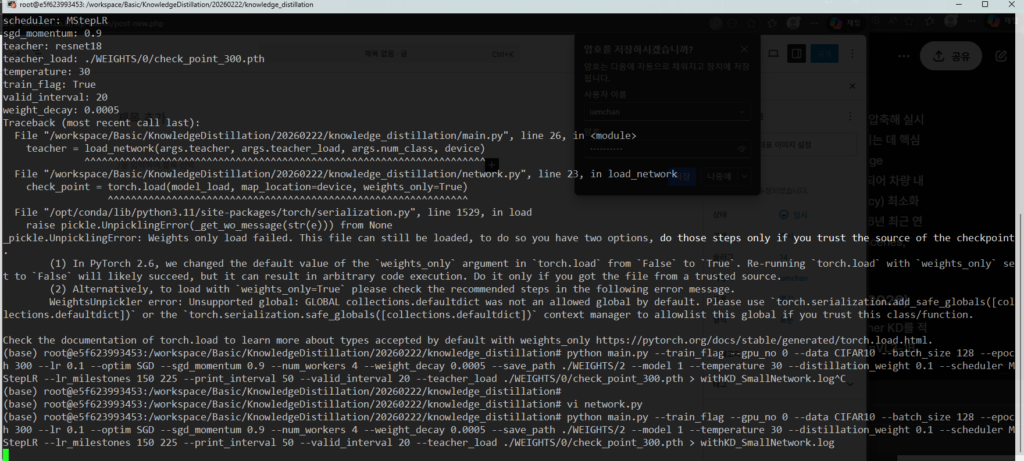
🏛️ Part 1: 논문
| 순번 | 논문 | 저자/연도 | 의의 | 표시 |
|---|---|---|---|---|
| 1 | Learning both Weights and Connections for Efficient Neural Networks | Han et al., NeurIPS 2015 | Pruning의 시초, iterative magnitude pruning | 🎯 |
| 2 | Deep Compression: Compressing Deep Neural Networks with Pruning, Trained Quantization and Huffman Coding | Han et al., ICLR 2016 | Pruning+Quantization+Huffman 통합 파이프라인 | 🎯 |
| 3 | Distilling the Knowledge in a Neural Network | Hinton et al., NIPS 2014 Workshop | Knowledge Distillation 개념 정립 | 🎯 |
| 4 | Quantizing deep convolutional networks for efficient inference: A whitepaper | Krishnamoorthi, 2018 (Facebook) | PTQ/QAT 실전 가이드, quantization 기초 총정리 | 🎯 |
✂️ Part 2: Pruning
| 순번 | 논문 | 의의 | 표시 |
|---|---|---|---|
| 5 | Pruning Filters for Efficient ConvNets (Li et al., ICLR 2017) | Structured pruning의 대표작 | 🎯 |
| 6 | The Lottery Ticket Hypothesis (Frankle & Carlin, ICLR 2019) | “Winning ticket” 개념, 필수는 아니지만 영향력 큼 | 📘 |
| 7 | To Prune, or Not to Prune: Exploring the Efficacy of Pruning for Model Compression (Li et al., 2017) | Pruning 한계 논의 | 📙 |
| 8 | Channel Pruning for Accelerating Very Deep Neural Networks (He et al., ICCV 2017) | 채널 단위 pruning | 📘 |
| 9 | Rethinking the Value of Network Pruning (Liu et al., ICLR 2019) | “Pruning은 architecture를 찾는 것” 통찰 | 📘 |
📌 읽는 순서 추천: 1 → 5 → 6 → 9
🔢 Part 3: Quantization
3-1. 양자화 기초/고전
| 순번 | 논문 | 의의 | 표시 |
|---|---|---|---|
| 10 | Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference (Jacob et al., CVPR 2018) | INT8 inference의 표준, TFLite/MobileNet 기반 | 🎯 |
| 11 | A White Paper on Neural Network Quantization (Krishnamoorthi, 2018) | 위와 거의 동일, 튜토리얼형 | 🎯 |
| 12 | Effective and Fast: A Novel Sequential Single-Path Search for Mixed-Precision Quantization — 대신 더 명시적인 다음 논문들 |
3-2. Mixed-Precision / HAQ 계열
| 순번 | 논문 | 의의 | 표시 |
|---|---|---|---|
| 13 | HAQ: Hardware-Aware Automated Quantization with Mixed Precision (Wang et al., CVPR 2019) | 하드웨어-인식 mixed-precision 자동 탐색 | 🎯 |
| 14 | HAWQ: Hessian AWare Quantization of Neural Networks with Mixed-Precision (Dong et al., ICCV 2019) | Hessian 기반 2차 정당화 | 📘 |
| 15 | HAWQ-V2: Hessian Aware trace-Weighted Quantization of Neural Networks (Dong et al., NeurIPS 2020) | trace-weighted, 더 발전된 mixed-precision | 📘 |
| 16 | HAWQ-V3: Dyadic Neural Network Quantization (Yvinec et al., ICML 2021) | dyadic scaling, hardware-friendly | 📙 |
3-3. PTQ (Post-Training Quantization) — 최근 핵심
| 순번 | 논문 | 의의 | 표시 |
|---|---|---|---|
| 17 | Up or Down? Adaptive Rounding for Post-Training Quantization (Li et al., ICML 2020) | AdaRound, PTQ 표준 기법 | 🎯 |
| 18 | Data-Free Quantization Through Weight Equalization and Bias Correction (Nagel et al., ICCV 2019) | Equalization + Bias Correction, 데이터 없는 PTQ | 🎯 |
| 19 | Improving Post Training Quantization Accuracy by Balancing Folds (Nagel et al., ICLR 2020) | activation distribution 보정 | 📘 |
| 20 | BRECQ: Pushing the Limit of Post-Training Quantization by Block Reconstruction (Li et al., ICLR 2021) | Block-wise 재구성, sharp vs flat minimizer 분석 | 🎯 |
| 21 | QDrop: Randomly Dropping Quantization for Extremely Low-bit Post-Training Quantization (Wei et al., NeurIPS 2022) | QAT 시뮬레이션 random drop, 2-bit PTQ | 📘 |
| 22 | GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers (Frantar et al., ICLR 2023) | LLM 4-bit PTQ의 표준, OBQ 일반화 | 🎯 |
📌 읽는 순서 추천: 10 → 17 → 18 → 20 → 22
🍵 Part 4: Knowledge Distillation (지식 증류)
| 순번 | 논문 | 의의 | 표시 |
|---|---|---|---|
| 23 | Distilling the Knowledge in a Neural Network (Hinton et al., 2014) | KD 원조 | 🎯 |
| 24 | FitNets: Hints for Thin Deep Nets (Romero et al., ICLR 2015) | Hint-based, intermediate feature 매칭 | 📘 |
| 25 | Paying More Attention to Attention: Improving the Performance of Convolutional Neural Networks via Attention Transfer (Zagoruyko & Komodakis, ICLR 2017) | Attention Transfer | 📘 |
| 26 | Born-Again Networks (Furlanello et al., ICML 2018) | 동일 크기 teacher→student | 📙 |
| 27 | Knowledge Distillation: A Survey (Gou et al., IJCV 2021) | Survey, 전반 조감 | 📘 |
🤖 Part 5: LLM 시대의 압축/양자화 (2023~)
| 순번 | 논문 | 의의 | 표시 |
|---|---|---|---|
| 28 | LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale (Dettmers et al., NeurIPS 2022) | Outlier 분리, mixed-precision | 🎯 |
| 29 | SmoothQuant: Accurate and Efficient Post-Training Quantization for Large Language Models (Xiao et al., ICML 2023) | W8A8, activation smoothing | 🎯 |
| 30 | AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration (Lin et al., MLSys 2024) | W4A16, activation-aware | 🎯 |
| 31 | GPTQ (위 22번, 중복) | ||
| 32 | SpQR: A Sparse-Quantized Representation for Near-Lossless LLM Weight Compression (Dettmers et al., ICLR 2024) | 희소+양자화 결합 | 📘 |
| 33 | QLoRA: Efficient Finetuning of Quantized LLMs (Dettmers et al., NeurIPS 2023) | NF4 + LoRA, 65B finetune on 1 GPU | 📘 |
| 34 | QuIP: 2-Bit Quantization of Large Language Models with Guarantees (Chee et al., NeurIPS 2023) | incoherence processing | 📘 |
| 35 | A Survey on Model Compression for Large Language Models (및 2024~ 다수 survey) | LLM 압축 survey | 📘 |
📌 읽는 순서 추천: 28 → 29 → 22 → 30 → 32 → 33
⚙️ Part 6: 실전/시스템 관점
| 순번 | 논문/자료 | 의의 | 표시 |
|---|---|---|---|
| 36 | Efficient Processing of Deep Neural Networks: A Tutorial and Survey (Sze et al., IEEE 2017) | 하드웨어-알고리즘 공동설계 | 📘 |
| 37 | MLPerf Inference Benchmark | 표준 벤치마크 | 📙 |
| 38 | ONNX Runtime Quantization docs | 실전 배포 | 📙 |
📅
| 주차 | 주제 | 논문 번호 |
|---|---|---|
| 1-2주 | 분야 조감 + KD 원조 | 3, 4, 23, 36 |
| 3-4주 | Pruning 고전 | 1, 2, 5, 6, 9 |
| 5-6주 | Quantization 기초 | 10, 11, 17, 18 |
| 7-8주 | Quantization 심화 | 13, 14, 20, 22 |
| 9-10주 | LLM 압축 | 28, 29, 30, 32, 33 |
| 11-12주 | Survey + 본 방향 결정 | 27, 35, 직접 탐색 |