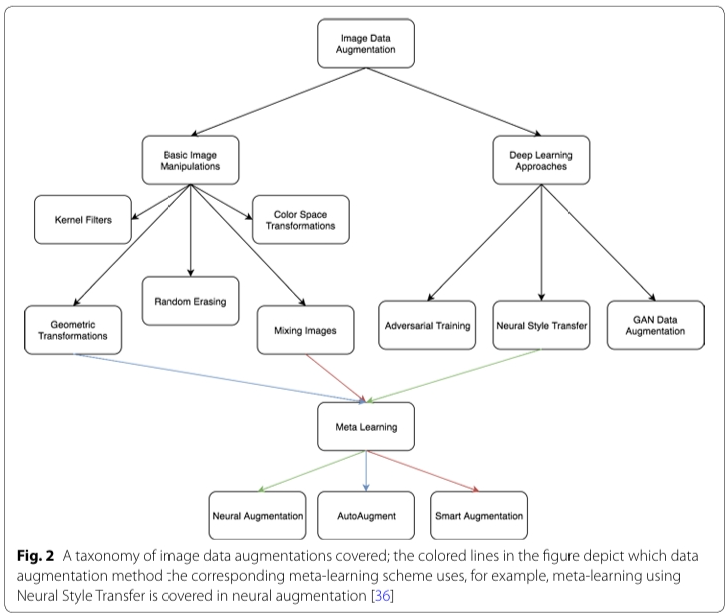
A Survey on Image Data Augmentation for Deep Learning.
A survey on Image Data Augmentation for Deep Learning | Journal of Big Data | Springer Nature Link
PDF 다운로드 : https://link.springer.com/content/pdf/10.1186/s40537-019-0197-0.pdf
[Abstract]
Deep Convolution Neural Network 는 컴퓨터 비전 과제에서 매우 놀라울 정도의 우수한 성과를 보였다. 하지만 이러한 네트워크는 과적합을 피하기 위해 빅데이터에 크게 의존하고 있다.
과적합은 네트워크가 학습 데이터를 완벽하게 모델링하는 매우 높은 분산을 가진 함수를 학습하는 현상이다.
데이터 증강은 학습 데이터 셋의 크기와 품질을 향상시키는 일련의 기법을 포함하여 이를 통해 더 나은 딥러닝 모델을 구축할 수 있도록 한다.(번역기 돌린 것 같은 문장이네..)
>>>>> 그러니까 이 연구에서 데이터 증강이란게 왜 필요하냐면,
제한된 데이터 환경에서 학습하게 되면, 분명히 과적합 문제가 발생할 확률이 높기 때문에
데이터 증강 방법을 통해서 데이터 수를 늘려서 학습하면 과적합 문제를 회피할 수 있을 것이다. 라는 말이다.
Data Argumentation은 데이터의 양을 늘리기 위해 원본 이미지에서 여러 변환 방법을 적용하여 그 이미지 개수를 늘린다. 증강시킨다.
컴퓨터 비전에서 CNN을 적용하여 현재 기준을 개선하려는 많은 연구 분야가 있는데, 이러한 모델의 일반화 능력을 향상시키는 것이 가장 어려운 과제 중 하나이다.
일반화 능력은 모델이 이전에 본 데이터(Training)와 전혀 본 적 없는 데이터(Test)를 평가할 때 그 성능의 차이를 의미한다.
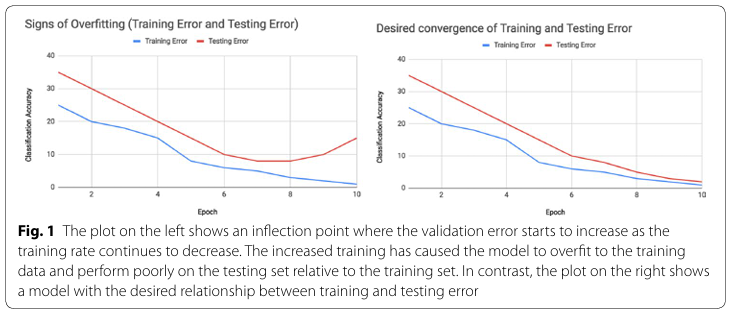
일반화 능력이 좋지 않으면 훈련데이터에 과적합(Over Fitting)이 된 것으로 볼 수 있다. 과적합을 발견하는 방법은 훈련 중에 각 epoch 에서 훈련 정확도와 검증(validation) 정확도를 그래프로 그리는 것이다.
위 Fig1. 그래프 처럼 말이다.