ICLR 2016, 1510.00149v5, Deep Compression: Compression Deep Neural Networks with Pruning, Trained Quantization and Huffman Coding
By Pruning the unimportant connections.
Quantizing the network using weight sharing.
Applying Huffman Coding.
Background or Motivation -> 2012년 이후 AlexNet, VGG와 같은 대규모 Conv NN 모델이 높은 성능을 달성했지만 모델의 크기가 너무 커서 모바일 장치에는 적합하지 않다고 판단. e.g., AlexNet 240MB, VGG-16 552MB 수백 메가 바이트의 모델을 스마트폰에 넣는다는 것은 앱의 용량, 메모리 사용량, 저장공간, 전력소비 등의 문제를 야기 시킨다. 특히, DRAM 접근은 연산하는것 보다 훨씬 많은 에너지를 소비한다.
Problem -> “모델 정확도는 유지하면서 저장공간, 메모리 대역폭을 크게 줄일 수 없을까?” 를 문제 대상으로 이를 해결하고자 한다.
2-1. 기존 CNN에서는 Redundancy 중복이 많다. 대표적으로 Parameter수가 너무 많다 (e.g., AlexNet 61MB, VGG16 138MB parameters) 대부분의 Parameter가 Fully Connected Layer에 집중되어 있다.
2-2. 저장공간 부족 모바일 장치에서의 저장공간은 PC보다 저장공간이 제한적이다.(메모리 램도 제한적이다)
2-3. 에너지 소비 -> FP32에서 Add는 0.9 pJ SRAM Access 5.0 pJ DRAM Access 640 pJ 즉, 메모리 접근이 연산보다 훨씬 비싸다. 따라서 Parameter의 수를 줄이는 것이 중요하다고 설명한다. 강조한다.
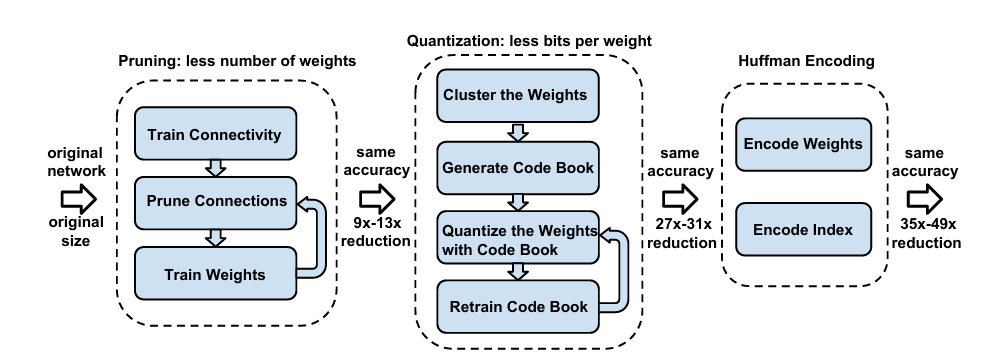
Method -> 이 논문에서의 핵심은 Deep Compression 이다 (3steps pipeline)
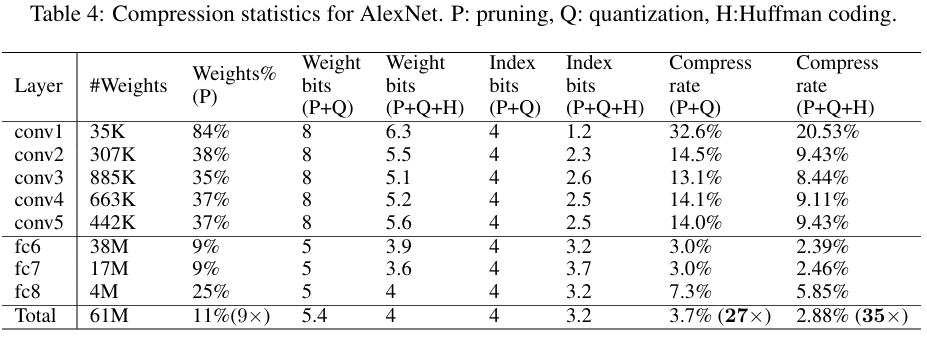
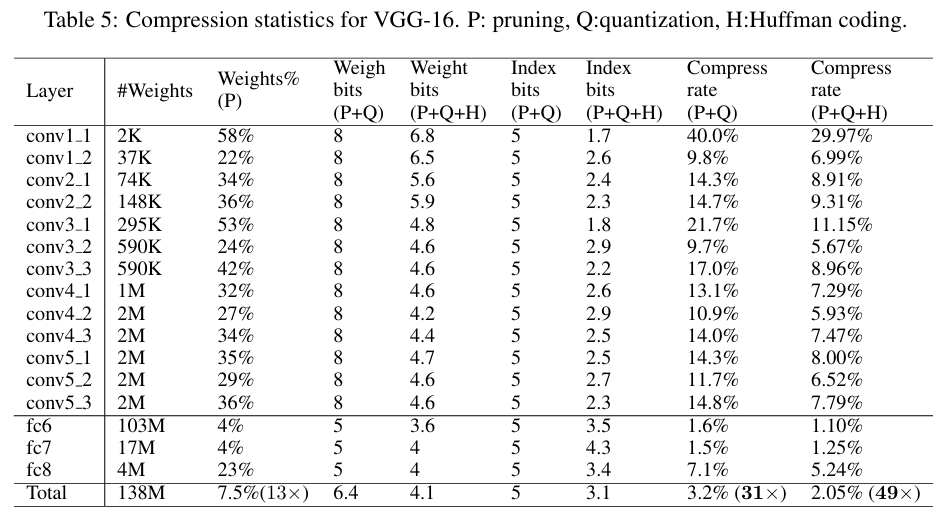
Step1. Pruning 중요하지 않은 연결을 제거한다. Dense Network 학습 -> Smallest weight delete(=Prune) -> Retraining 결과: AlexNet은 약 9배 감소, VGG16은 약 13배 감소됨.
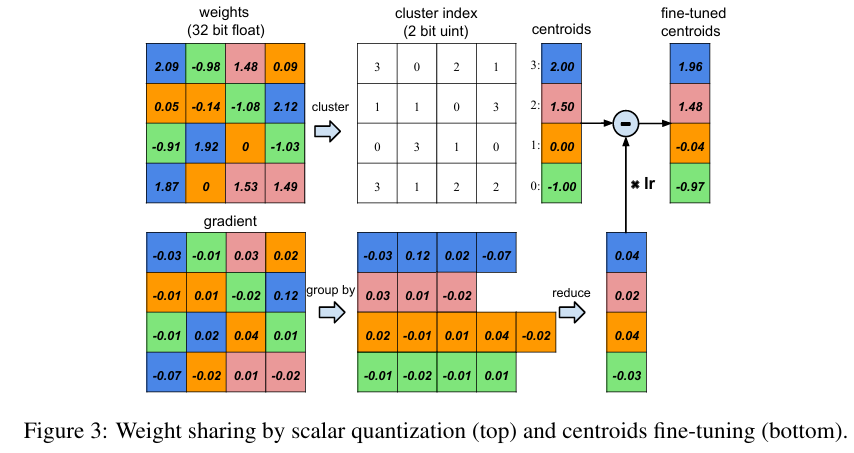
Step2. Quantization + Weight Sharing Pruning 후에 weight를 압축한다. 학습된 모델에서 Threshold 값을 정한 뒤, 이 값 보다 작은 weight의 연결을 제거.
e.g., “0.49, 0.51, 0.48, 0.50” 의 weight 경우 0.50으로 요약해서 공유 한다. 비슷한 값을 가진 weight이기 때문에 라는 아이디어.